Modelos de Lenguaje Visual: Entrenamiento desde Cero en 2026
Modelos de Lenguaje Visual: Entrenamiento desde Cero en 2026
iamanos.com: Expertos en Inteligencia Artificial de alto calibre. Traemos la tecnología más avanzada del mundo a tu alcance, explicada con claridad estratégica. Los modelos que hoy leen imágenes como un especialista no nacieron así: fueron construidos con una arquitectura precisa, capa a capa. Entender ese proceso no es un lujo académico; es una ventaja competitiva real. En iamanos.com, convertimos esta ingeniería de frontera en decisiones de negocio accionables.
Por qué los Modelos de Lenguaje Visual Marcan un Antes y un Después
Durante años, los lenguaje-aws-2026/” target=”_blank” rel=”noopener noreferrer”>modelos de lenguaje operaron en un único canal sensorial: el texto. Eran brillantes analizando contratos, redactando informes o razonando sobre datos estructurados, pero completamente ciegos ante una imagen de rayos X, un plano arquitectónico o una captura de pantalla de un error en producción. En 2026, esa limitación ya es historia.
Los modelos de lenguaje visual —denominados en la literatura técnica como modelos multimodales de visión y lenguaje— representan la convergencia de dos disciplinas que durante décadas avanzaron por separado: la visión por computadora y el procesamiento de lenguaje natural. El resultado es un sistema capaz de leer, interpretar y razonar sobre imágenes con la misma fluidez con la que razona sobre texto.
Se estima que para finales de 2026, más del 60% de los nuevos despliegues empresariales de modelos de inteligencia artificial incluirán capacidades visuales como requisito funcional mínimo. Para los directores de tecnología, esto no es una predicción lejana: es una especificación de compra que ya está en las licitaciones de este trimestre.
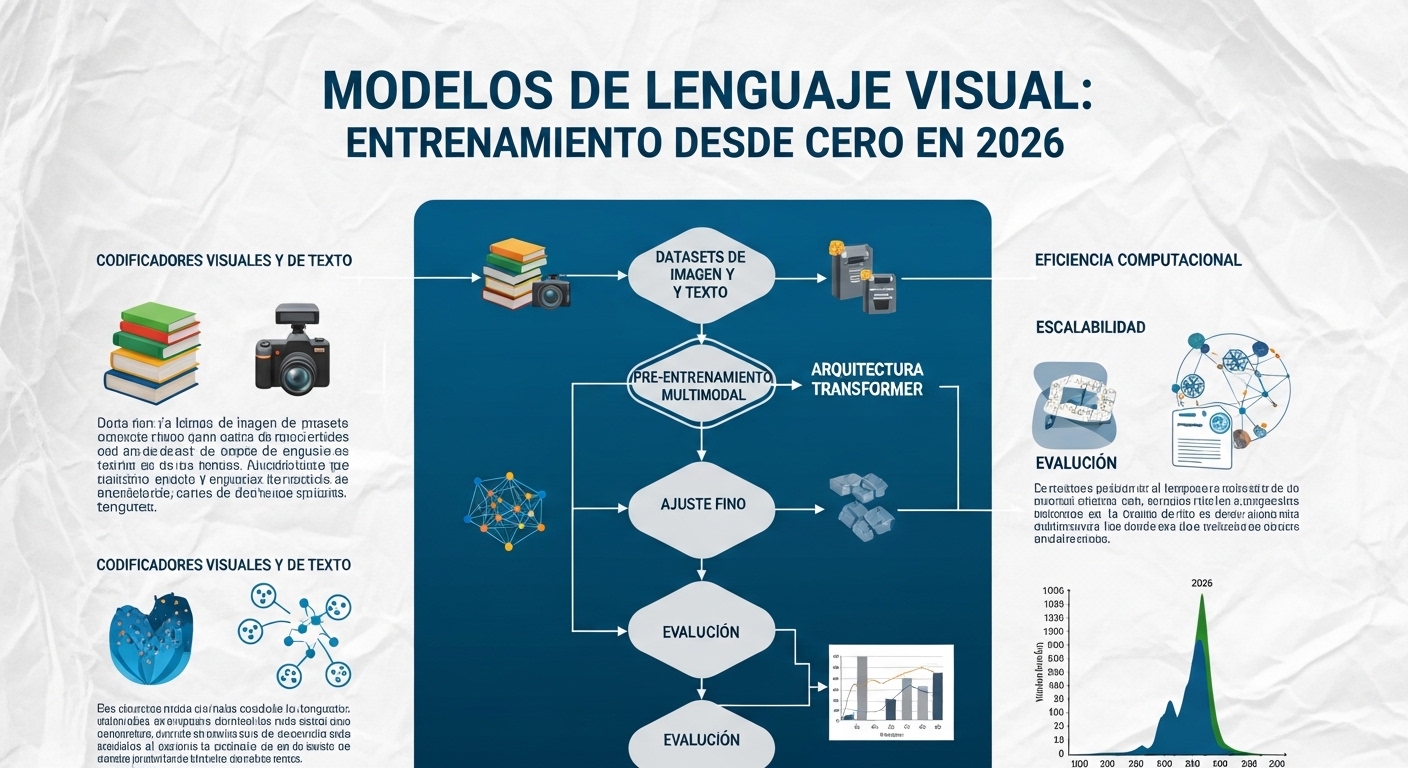
Pero ¿cómo se construye un modelo que ve y habla? El proceso tiene tres fases críticas que todo líder tecnológico debe entender antes de evaluar un proveedor o contratar un equipo de desarrollo.
La Brecha entre Ver y Entender
Un modelo de lenguaje convencional procesa secuencias de tokens —fragmentos de texto codificados numéricamente. Una imagen, en cambio, es una matriz tridimensional de píxeles. Para que ambos mundos se comuniquen, se necesita un traductor arquitectónico. Ese traductor es el codificador visual: una red neuronal —típicamente basada en la arquitectura de transformador de visión— que convierte los píxeles de una imagen en vectores de alta dimensión, llamados representaciones latentes, que el modelo de lenguaje puede interpretar como si fueran palabras.
Esta traducción no es trivial. El codificador visual debe aprender qué características de la imagen son semánticamente relevantes —bordes, objetos, relaciones espaciales, texto incrustado— y representarlas en un espacio matemático compatible con el que el modelo de lenguaje ya domina. Ese aprendizaje ocurre en la primera fase del proceso: el preentrenamiento.
Las Tres Etapas del Entrenamiento: Una Guía Técnica para Ejecutivos
El proceso completo que convierte un modelo de texto en un modelo capaz de interpretar imágenes, tal como lo documenta Towards Data Science en su análisis técnico de referencia, se articula en tres etapas secuenciales y complementarias. Ignorar cualquiera de ellas produce lenguaje-aws-2026/” target=”_blank” rel=”noopener noreferrer”>modelos frágiles, inconsistentes o directamente inútiles en producción.
Primera Etapa: Preentrenamiento a Gran Escala
El preentrenamiento es la fase de máximo consumo de cómputo y la que determina el techo de capacidad del modelo resultante. En esta etapa, el sistema aprende a asociar imágenes con descripciones textuales utilizando conjuntos de datos masivos —del orden de cientos de millones o incluso miles de millones de pares imagen-texto recopilados de la web.
El objetivo técnico de esta fase es aprender una representación compartida: un espacio matemático en el que la imagen de un gato y la frase ‘un gato naranja sobre una silla’ se sitúen cerca el uno del otro. Este principio, popularizado por lenguaje-aws-2026/” target=”_blank” rel=”noopener noreferrer”>modelos como CLIP, es la base sobre la que se construye toda capacidad visual posterior.
En términos de infraestructura, esta etapa requiere clústeres de procesadores gráficos especializados que operan durante semanas o meses. Para las empresas que evalúan construir capacidades propias frente a consumir modelos de terceros, este dato tiene implicaciones presupuestarias directas: el preentrenamiento desde cero no está al alcance de la mayoría de organizaciones. La estrategia ganadora en 2026 es partir de modelos base ya preentrenados y personalizarlos.
Segunda Etapa: Alineación Multimodal con Proyectores
Una vez que el codificador visual y el modelo de lenguaje existen por separado —cada uno preentrenado en su dominio— el desafío es conectarlos de forma que puedan comunicarse fluidamente. Aquí entra en juego un componente arquitectónico llamado proyector o módulo de conexión.
El proyector es una red neuronal relativamente compacta cuya única misión es traducir las representaciones vectoriales que produce el codificador visual al espacio de tokens que entiende el modelo de lenguaje. En esta etapa de alineación, el sistema aprende a mapear conceptos visuales complejos —”el objeto de la izquierda es más grande que el de la derecha”, “el texto del recibo dice 47.50″— en representaciones que el motor de lenguaje puede procesar como si fueran frases.
Esta fase es significativamente más económica en cómputo que el preentrenamiento, pero requiere datos de alta calidad: conjuntos curados de imágenes con descripciones precisas, pares de preguntas visuales con respuestas verificadas, y documentos que combinan texto e imágenes de forma estructurada. La calidad del dato en esta etapa es el factor que más diferencia a los modelos de producción de los modelos de laboratorio.
Para quienes trabajan en proyectos de automatización empresarial —procesamiento de facturas, análisis de planos, control de calidad visual— esta es la etapa donde se decide si el modelo entenderá su dominio específico o fallará ante los primeros documentos reales.
Tercera Etapa: Ajuste Fino con Instrucciones Multimodales
La última etapa transforma un modelo que “entiende” imágenes en un modelo que puede seguir instrucciones complejas sobre ellas. Técnicamente, esto se logra mediante ajuste fino supervisado con datos de instrucción multimodal: miles de ejemplos del formato “Dada esta imagen, responde esta pregunta de esta manera”.
Esta fase incorpora además técnicas de aprendizaje por refuerzo con retroalimentación humana, el mismo principio que hace que los modelos de lenguaje conversacionales sean útiles y seguros. En el contexto visual, esto significa que evaluadores humanos califican las respuestas del modelo sobre imágenes, y ese feedback se usa para ajustar el comportamiento del sistema hacia respuestas más precisas, más honestas sobre sus limitaciones visuales y más alineadas con las instrucciones del usuario.
El resultado final es un modelo que puede analizar una fotografía de infraestructura y detectar anomalías, leer un estado de cuenta escaneado y extraer campos estructurados, o interpretar un diagrama técnico y responder preguntas de diagnóstico. Esto es precisamente lo que organizaciones de manufactura, salud y finanzas están desplegando en producción hoy.
Implicaciones Estratégicas para Directores de Tecnología en 2026
Comprender el proceso de entrenamiento de los modelos de lenguaje visual no es un ejercicio académico. Es la diferencia entre tomar decisiones de arquitectura informadas y quedar atrapado en ciclos de evaluación interminables. Hay tres decisiones críticas que todo director de tecnología enfrenta en 2026 al respecto.
Construir, Ajustar o Consumir: La Decisión Arquitectónica Central
La estrategia de preentrenamiento desde cero está reservada para organizaciones con recursos de cómputo masivos y casos de uso que justifican la inversión —típicamente laboratorios de investigación o grandes corporaciones tecnológicas. Para el 95% de las empresas, la decisión es entre ajustar un modelo base existente o consumir un modelo multimodal como servicio.
El ajuste fino —en sus variantes de alineación multimodal y ajuste con instrucciones específicas del dominio— es la ruta óptima para organizaciones con datos propietarios únicos: imágenes de componentes industriales que ningún modelo público ha visto, documentación médica en formatos institucionales específicos, o catálogos de productos con convenciones visuales particulares. Este ajuste puede realizarse en infraestructura modesta con los marcos de trabajo adecuados, y los resultados superan consistentemente a los modelos genéricos en contextos especializados.
Para quienes evalúan optimizar sus costos de inferencia y latencia, es importante entender que los modelos de lenguaje visual son significativamente más demandantes en recursos que sus equivalentes de solo texto. Tecnologías como el almacenamiento en caché de instrucciones y las técnicas de inferencia acelerada con decodificación especulativa paralela se vuelven componentes de optimización indispensables en cualquier despliegue visual a escala.
La Calidad del Dato Visual es el Nuevo Activo Estratégico
Una conclusión directa del análisis del proceso de entrenamiento es que los datos curados de alta calidad —especialmente en las etapas de alineación y ajuste fino— tienen un impacto desproporcionado en el rendimiento final del modelo. Las organizaciones que ya cuentan con repositorios de imágenes etiquetadas, documentos escaneados con metadatos ricos, o historial de interacciones visuales con clientes, poseen un activo competitivo que sus competidores no pueden replicar simplemente comprando más cómputo.
Esto tiene implicaciones directas para la estrategia de datos de cualquier empresa con ambiciones de construir capacidades de inteligencia artificial propias. El inventario de datos visuales debe tratarse con el mismo rigor de gobernanza que los datos financieros o los datos de clientes. Organizaciones como Wayfair, que ha desplegado catálogos inteligentes a escala industrial, lo entendieron antes que sus competidores.
Evaluación Rigurosa: Los Benchmarks que Importan en Producción
Un error frecuente en los procesos de evaluación de modelos multimodales es medir rendimiento con benchmarks académicos estándar que poco tienen que ver con el caso de uso real de la organización. Los modelos de lenguaje visual tienen perfiles de capacidad muy heterogéneos: un modelo puede ser excelente describiendo escenas naturales y mediocre interpretando diagramas técnicos, o viceversa.
La evaluación rigurosa debe construirse con muestras representativas de los datos reales de la organización, con métricas específicas al dominio —precisión en extracción de campos, coherencia en descripciones técnicas, tasa de alucinaciones sobre elementos visuales— y con pruebas de robustez ante imágenes degradadas, mal iluminadas o con formatos poco convencionales.
Este nivel de rigor en la evaluación es la diferencia entre un piloto exitoso y un despliegue en producción que falla ante los primeros usuarios reales. En iamanos.com hemos visto demasiados proyectos de inteligencia artificial —visuales y de otro tipo— que superaron todas las pruebas de laboratorio y colapsaron en producción por falta de este rigor. El enfoque técnico para construir sistemas de inteligencia artificial pragmática para el mundo real aplica con especial fuerza en el dominio visual.
El Horizonte de los Modelos Visuales: De la Comprensión a la Acción
El entrenamiento de modelos de lenguaje visual desde cero está evolucionando hacia algo más ambicioso: modelos que no solo interpretan imágenes sino que actúan sobre el mundo visual. Los sistemas de agentes autónomos que navegan interfaces gráficas, inspeccionan entornos físicos a través de cámaras, o interpretan documentos en tiempo real para tomar decisiones operativas, son ya una realidad en despliegues de vanguardia.
Esta convergencia entre percepción visual y agencia autónoma está redefiniendo lo que significa automatizar un proceso de negocio. Ya no se trata solo de procesar texto estructurado; se trata de percibir el entorno con la riqueza con la que lo percibe un operador humano experto y actuar en consecuencia. Organizaciones en manufactura que ya han desplegado inteligencia artificial física en sus líneas de producción están comenzando a integrar capacidades visuales como la siguiente capa de sofisticación.
Las predicciones más conservadoras del sector estiman que para 2027, los modelos de lenguaje visual con capacidad de acción autónoma sobre interfaces gráficas eliminarán o transformarán sustancialmente el 30% de los roles de procesamiento de datos en sectores como seguros, logística y servicios financieros.
En iamanos.com diseñamos e implementamos estas arquitecturas hoy, no en 2027. Si tu organización está evaluando incorporar capacidades visuales a sus sistemas de inteligencia artificial, la conversación estratégica debe comenzar con un diagnóstico de madurez de datos, una evaluación de casos de uso de mayor impacto y un análisis de la infraestructura de inferencia disponible.
Puntos Clave
Los modelos de lenguaje visual no son una versión más potente de los modelos de texto: son una arquitectura fundamentalmente diferente que requiere decisiones de entrenamiento, datos y evaluación distintas. Las organizaciones que comprendan a fondo las tres etapas —preentrenamiento a gran escala, alineación multimodal con proyectores y ajuste fino con instrucciones visuales— tomarán decisiones de compra, construcción y despliegue significativamente superiores a las que traten estos sistemas como cajas negras intercambiables. En 2026, la ventaja competitiva no la tiene quien más gasta en inteligencia artificial, sino quien más entiende lo que está comprando. En iamanos.com, esa comprensión es nuestra propuesta de valor central: el nivel técnico de Silicon Valley con la claridad estratégica que exige la dirección ejecutiva.
Lo que necesitas saber
Un modelo de lenguaje visual es un sistema de inteligencia artificial capaz de procesar y razonar sobre imágenes y texto de forma simultánea. A diferencia de los modelos de lenguaje convencionales, que operan exclusivamente sobre texto, un modelo visual incorpora un codificador de imágenes que convierte píxeles en representaciones matemáticas compatibles con el motor de lenguaje, permitiendo responder preguntas sobre imágenes, describir contenido visual o extraer información de documentos escaneados.
El preentrenamiento desde cero de un modelo de lenguaje visual de escala competitiva requiere inversiones que oscilan entre varios millones y decenas de millones de dólares en infraestructura de cómputo especializado, además de meses de tiempo de entrenamiento. Para la gran mayoría de organizaciones, la estrategia óptima es partir de un modelo base preentrenado y realizar ajuste fino con datos propios del dominio, lo que reduce el costo en varios órdenes de magnitud.
Para la etapa de alineación multimodal y ajuste fino, se requieren conjuntos de datos curados de alta calidad: pares de imágenes con descripciones o respuestas precisas representativas de tu dominio específico. La cantidad varía según la complejidad del caso de uso, pero conjuntos de entre 10,000 y 100,000 ejemplos bien etiquetados suelen ser suficientes para obtener mejoras significativas sobre modelos genéricos en aplicaciones especializadas como procesamiento de documentos, control de calidad visual o análisis de imágenes médicas.
La evaluación rigurosa debe realizarse con muestras representativas de tus datos reales, no solo con los benchmarks estándar del proveedor. Define métricas específicas a tu caso de uso —precisión en extracción de campos, tasa de errores en interpretación de documentos, coherencia en descripciones técnicas— y prueba el modelo con ejemplos que representen los casos más difíciles y frecuentes de tu operación real. Los modelos que superan pruebas genéricas frecuentemente fallan ante las particularidades de datos empresariales reales.
En 2026, los sectores con mayor adopción y retorno documentado de modelos de lenguaje visual son manufactura —control de calidad automatizado e inspección visual—, servicios financieros y seguros —procesamiento de documentos escaneados y extracción de datos de formularios—, salud —análisis de imágenes diagnósticas y documentación clínica—, y comercio electrónico —clasificación y descripción automática de catálogos de productos. En todos estos casos, el elemento común es la existencia de grandes volúmenes de imágenes con valor informacional que anteriormente requerían procesamiento manual.
Convierte este conocimiento en resultados
Nuestro equipo implementa soluciones de IA para empresas B2B. Agenda una consultoría gratuita.